

When it comes to consuming media, there are two types of people: Streamers and Keepers. Streamers are people who consume media via streaming services and have no desire to retain copies of those things. Keepers are people who feel a need to keep a copy of the media they consume, be it in physical or digital format. Streamers are perfectly content to watch movies on Netflix and listen to music on Spotify and feel no sense of loss if or when, like dust in the wind, those things disappear from streaming services. Keepers are still buying physical media and continually filling hard drives with digital copies of movies and music.
While it would certainly be more convenient to be a Streamer, I am, in my heart, a Keeper. It bothers me that streaming services routinely drop old content from their libraries and replace them with new things. Next month Netflix will be removing the first five seasons of the Twilight Zone, Back to the Future 1-3, and Twin Peaks from their platform. That doesn’t seem to bother Streamers, who will just move along and watch something else. It doesn’t bother me as a Keeper, either, since I own all of those things on DVD and/or Blu-ray, have copied them to my media server, and can watch them anytime I want.
Podcasts, another form of media, are considered by most people to be disposable — after listening to an episode, many (most?) people delete it and move on to the next one. Compounding the issue, cell phones, the most popular way to listen to podcasts, have a finite amount of storage space. I currently subscribe to more than 50 podcasts, many of which release at least one new episode each week. If I were to save every episode of every podcast I listened to, my phone would would run out of space very quickly. The podcatcher I use for my phone (Downcast) only saves the latest five episodes of each show by default, and older episodes can be redownloaded or streamed from the original source.
But… what happens when the original source disappears? Many years ago there was a retro computing podcast called the Boring Beige Box that I absolutely adored. Matt Wilson, the show’s host, owned a PC in the late 80s and early 90s and shared his memories and stories from those times. As sometimes happens, Matt eventually lost interest in podcasting. The episodes were hosted on a pay service, and when he stopped paying the bill, they disappeared. Unless you had local copies of the episodes stored on your computer, there was no way to listen to them ever again. Sadly, this is not terribly uncommon. I remember one podcast where after the hosts had a falling out, one of them deleted every episode of their show from their webhost. Gone forever. I had another friend who, for personal reasons, removed 300+ episodes of his podcasts from the internet. In some cases, episodes of these shows were saved by listeners and archived online. In other cases, they were instantly expunged from existence.
That doesn’t work for Keepers.
Many years ago, I found a program that would download podcasts and save them on my computer. It was complicated to use and had almost no bells or whistles, but it worked. Mostly. Later I found a second program that was a little easier to use, but still didn’t do everything I wanted. Eventually I decided the only way to get everything I wanted in a podcatcher was to write my own.
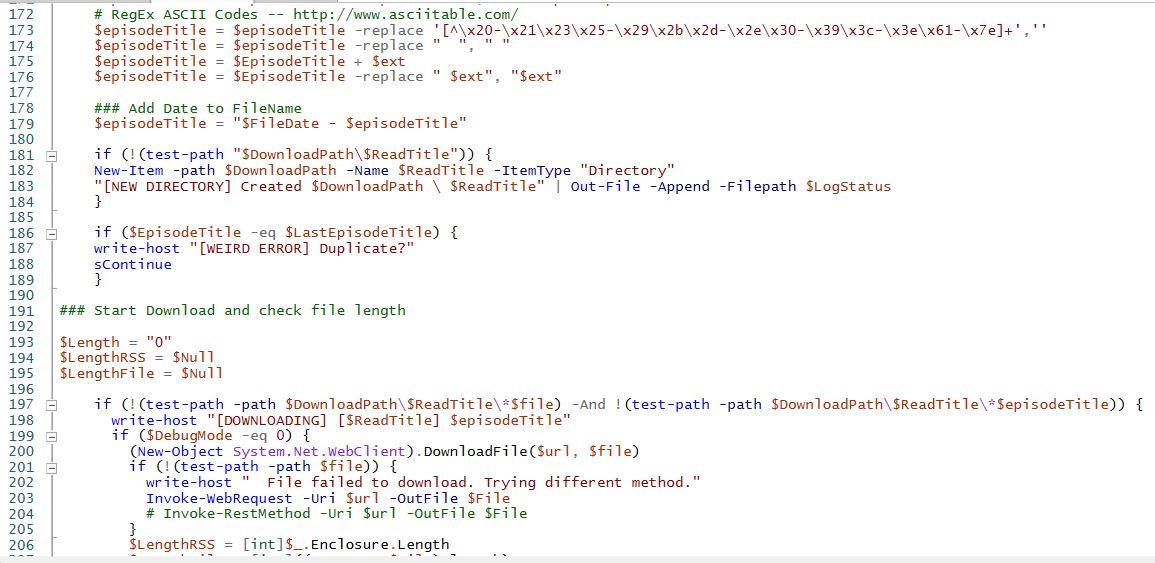
The “program” I wrote (it’s really a PowerShell script) was called RobCast. I’ve been using it for the past two years, and a week hasn’t gone by that I haven’t had to fiddle with it. RobCast was designed to read a series of podcasts from a text file and download any new episodes it detected. The script worked great when things went how they were supposed to. The problem is, things rarely go how they’re supposed to, and the script doubled (and eventually tripled) in length as I continued modifying it to handle exceptions. For example:
- The script worked great until a feed I had in my list became unavailable. I had to add code to make sure that what I thought was an RSS feed actually was an RSS feed.
- Early on I made the assumption that all podcasts would be in mp3 format. This worked great until the first .m4a file arrived.
- I wanted released episodes to be listed by release date, which meant appending the date to the front of each episode. To make this uniform, this meant converting every month (sometimes abbreviated, sometimes not) to a two digit code, converting all dates to two digits, and converting all years to two digits. Nobody’s XML feed is identical, and I had to tweak this part over and over as new exceptions to the rule were discovered.
- I renamed every file with the show’s title instead of the file name… except some people don’t include a show title, because they are animals. So I had to deal with that.
- Lots of podcasters put apostrophes and back slashes and all kinds of characters in their show titles which aren’t valid characters in file names, so I had to write a bunch of “replace” functions to remove them.
- Sometimes, a download would abort for unknown reasons, leaving me with a corrupt file. I discovered that podcast feeds contain file lengths, so I wrote some code to compare the reported length of the file to the actual length of the file. What I quickly learned was, those numbers aren’t accurate. Some hosting websites add advertisements to their shows, so the length presented in the feed is the length of the file before the advertisement was added. Some feeds don’t include the length at all. And then I found multiple feeds that were being manually generated where every episode was listed as being the same length, which means people were literally lying. Animals!
Along the way I added a few neat features to Robcast. One, called “leech mode,” downloads every episode in a podcast’s feed — handy for archiving a a show’s entire run, or grabbing all the back episodes of a show you’ve just discovered. I did a couple of other neat things, but more often than not, most of the work I put into the thing was just to keep it working.
Every few months I would get so fed up with the thing that I would search Google to look for alternatives. There were and are several available, but none of them seemed to do what I wanted them to do. Even the ones that worked didn’t seem to present things in a logical format.
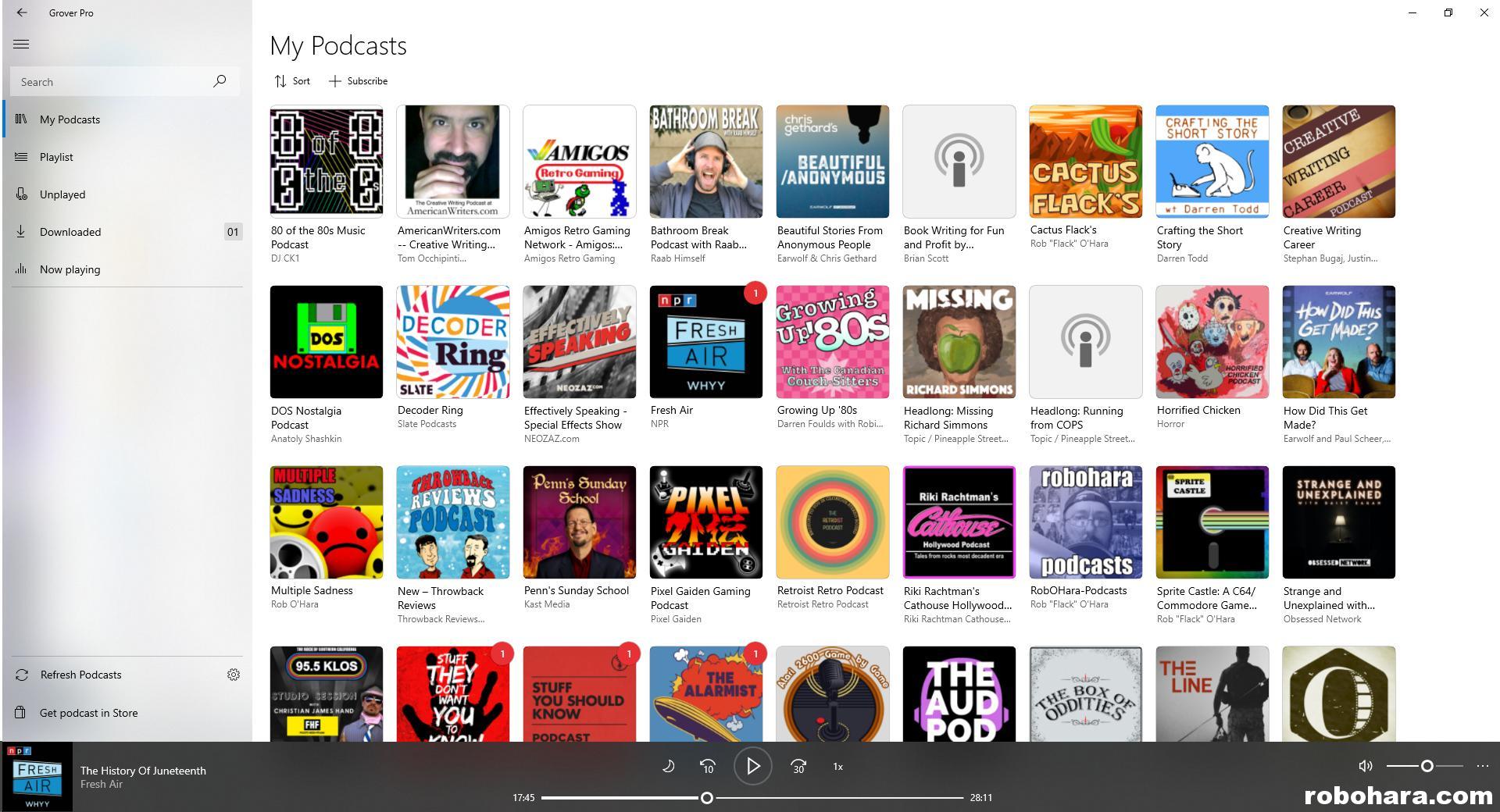
Last week I found a new one (to me) called Grover. I decided to check it out and all I can say it, whoever wrote this program thinks (or at least organizes things) like I do. New episodes are added to an “unplayed” folder and a default playlist. Podcast feeds are easy to add. Podcast refreshes can be scheduled. Frankly it does everything my script does but better, with a slick graphical interface to boot.
The default version of Grover is free. The professional version, which includes additional features such as the ability to update feeds in the background, limit the number of episodes to keep (per feed), and the ability to sync subscriptions through OneDrive, costs $3. The program is available for Windows 10 and some other Microsoft operating systems (even the Xbox), which met my needs.
Earlier this week I purchased Grover Pro and have been running both it and RobCast in parallel. Grover Pro hasn’t failed me yet, and in many (most?) ways works much better than the script I wrote. No more checking logs every morning to see if my script ran properly or not. No more messing with code each time someone decided to add a question mark to their show’s title. No more checking each show to see if it properly downloaded.
This morning, I disabled the daily scheduled task that runs RobCast, and I couldn’t be happier. I never wanted to write my own podcatcher — I did so out of necessity. I’m not jealous that someone did it better than I could. I’m grateful.
I regret not saving a lot of podcasts I first started listening too when podcasting was new. With only a couple exceptions they are all gone, and I have no idea how to contact the podcasters who made them. As much as I consider myself a digital hoarder, I need to start doing this to podcasts I like that I would be bummed out if they disappeared.
We managed to be streamers throughout the DVD/Blu-ray era. We have less than 50 discs total, none of them Blu-ray. However, once I started using Plex, I became a limited keeper. My plan was to keep only favorite shows and movies.
Since I got PosterPi working, I have felt impelled to make the Plex collection include the movies represented in the PP image collection.
The same thing had already happened with music. I created an album cover image collection to be displayed on Chromecast in a similar way to PosterPi, and wound up trying to have copies of all those in Plex.
What really kicked me into higher gear on music was the Plex skill on Alexa. Anything can be played on request, like your own version of Spotify without the monthly fee ad infinitum.
(Emby has a similar skill, though it is much harder to set up. Worth it though, because their “random” play is more truly random, and I set it up to draw from all my separate Plex music music libraries.)